Why Activation Functions Matter


Image source: Adapted by author from source.
Neural network is the algorithm behind deep learning, and especially the Generative AI we see today. Convolutional Neural Networks used to be very popular for deep learning with images because it can recognize patterns on images. Recurrent Neural Networks used to be very popular for text modelling because it can understand sequences.
Source: Rukshan Pramoditha
However, these architectures have quickly become obsolete since the invention of Transformers in 2017, which is the architecture behind most large language models today.

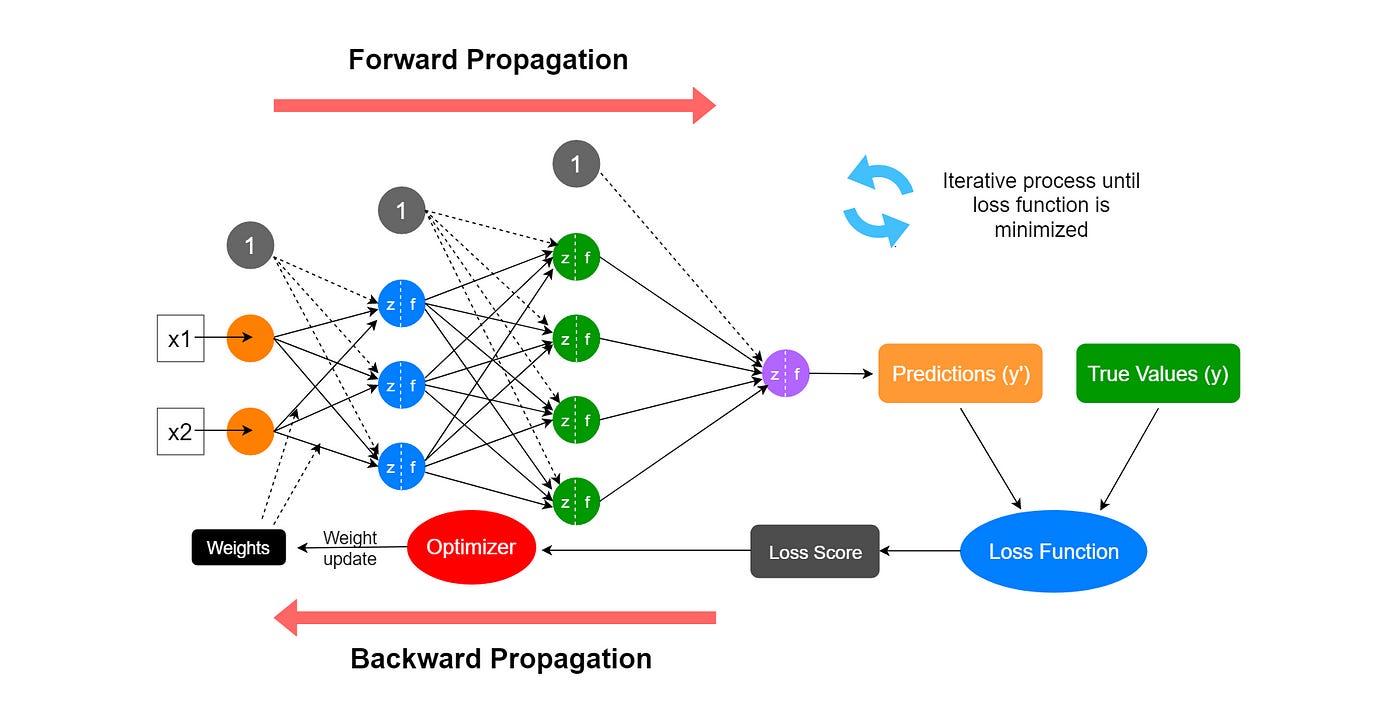
The transformer looks scary, but the Math is actually quite simple, it is mostly matrix multiplication! In a nutshell, modern deep learning models consist of repeatedly applying the following operations:
1. Matrix multiplication (Linear Algebra)
2. Activation function (Non-linear transformation)
3. Normalization/pooling (Simple Statistics)
When we read about the billions of parameters that a model consists of, we talk about weights and biases, which are represented as a large collection of matrices and vectors. Before the attention, an LLM first turns each token into a vector. Then most of the hard work that an AI performs is multiplying matrices with other matrices and vectors, which, at its core, performs many dot products.
But matrix multiplication alone is not enough. The multiplication of thousands of matrices would result in a single matrix that we can precompute, and the whole transformer architecture would reduce to a single matrix multiplication between a token embedding matrix and a precomputed hidden layer matrix. And most importantly, matrix multiplication is basically a linear regression model, so it will be impossible to learn any complex patterns.
Therefore, in each layer in the network, between each matrix multiplication step, the AI must perform an activation function to introduce non-linearity. Without this step, stacking multiple layers would be pointless. It would just be one big linear transformation. The most common choices are Softmax, ReLu, sigmoid tanh functions.

Activation function makes deep learning possible. But only good activation functions make it trainable.
Gradient Descent
The goal of training any model is to minimize the loss (the measurement of its errors). How is the loss minimized? Through gradient descent.
The idea of gradient descent is simple: You start with an initial guess for the model’s parameters (weights) and keep updating them to minimize the loss. Each step moves in the direction that reduces the error.
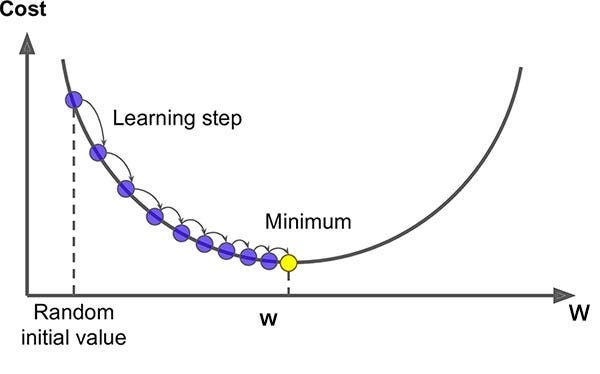
How does the model know how to adjust each weight?
👉 By using derivatives. (Yes — high-school math 🙂)
Gradient descent uses the gradient of the loss function as a learning signal to update the weights. In each step, you compute the gradient → update the weight → having new (hopefully smaller) loss.
So how does the activation function fit in?
Activation functions control how the learning signal flows backward.
Gradients of the loss function are computed using derivatives with the chain rule. One of the terms in this chain is the derivative of the activation function. The shape of the activation function directly affects the strength of the gradient signal flowing backward.
If the gradient is:
Large → learning is strong, you pass the minimum
Small → learning slows, you get stuck
Zero → learning stops
Most common activation functions
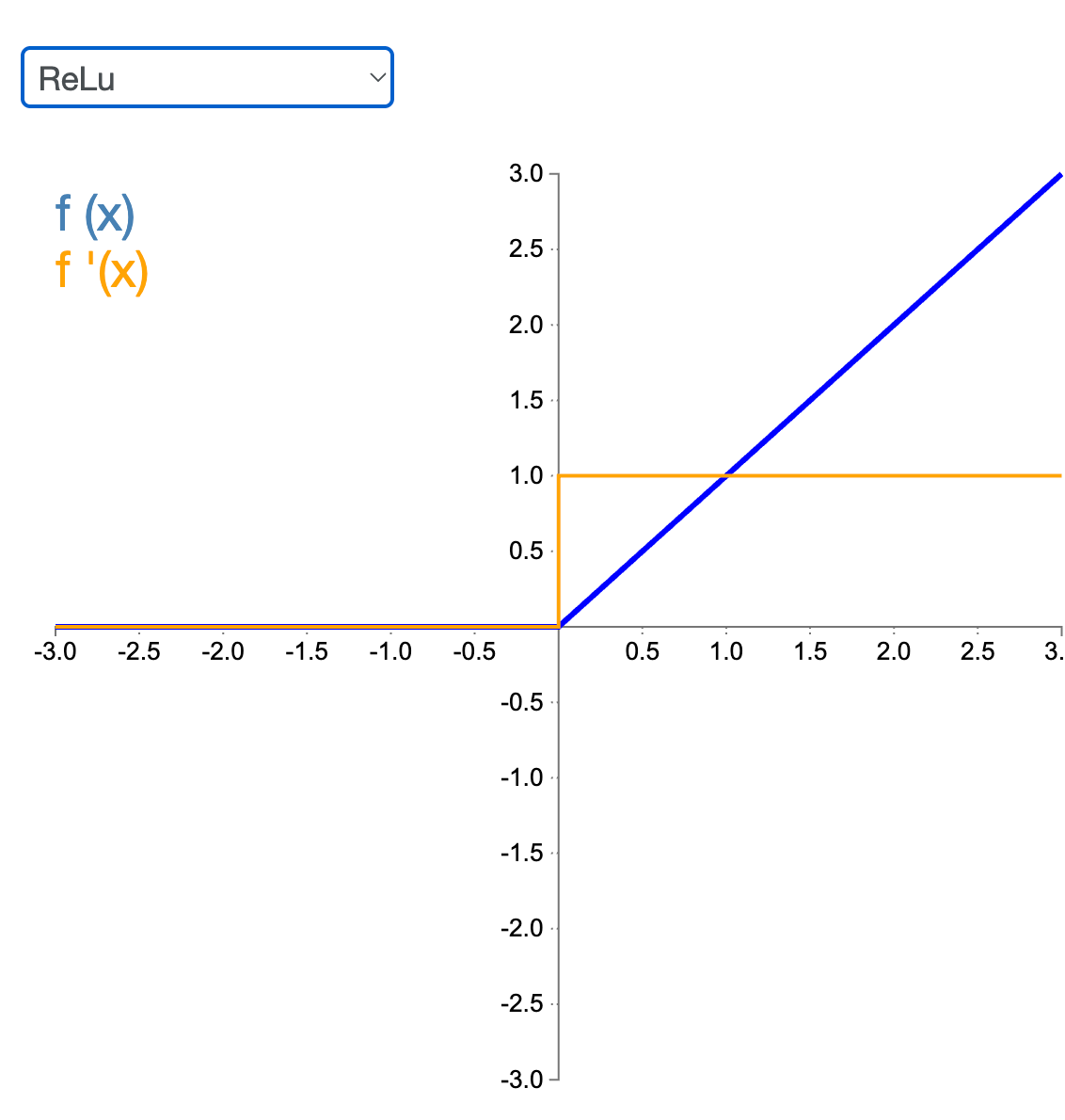
ReLU
ReLU (y = max(0, x)). The easiest non-linear function you can think of: 0 for negative values, and linear for positive values.
The gradient is 1 for all positive values and 0 otherwise. It's quick to compute due to the simple function and its derivative. However, as the derivative is 0 at non-positive inputs, if a neuron keeps seeing negative inputs, its gradient becomes zero
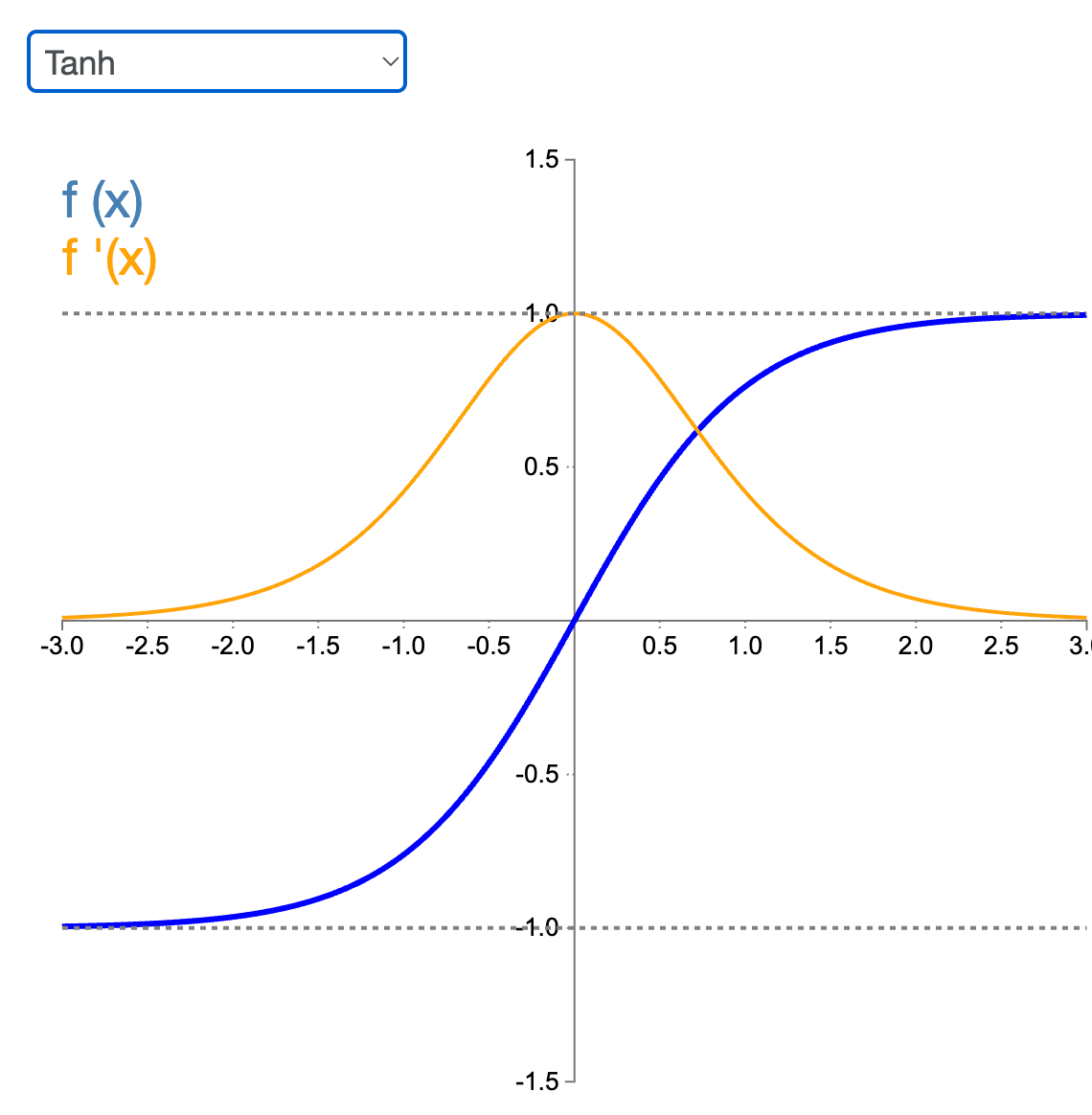
Tanh
Tanh is S-shaped like a sigmoid, but its output value ranges from -1 to 1 (instead of 0 to 1 in a sigmoid). That range makes each layer’s output more or less centered around 0 at the beginning of training, which often helps speed up convergence.
It is commonly used in hidden layers of RNNs, LSTMs and GANs.
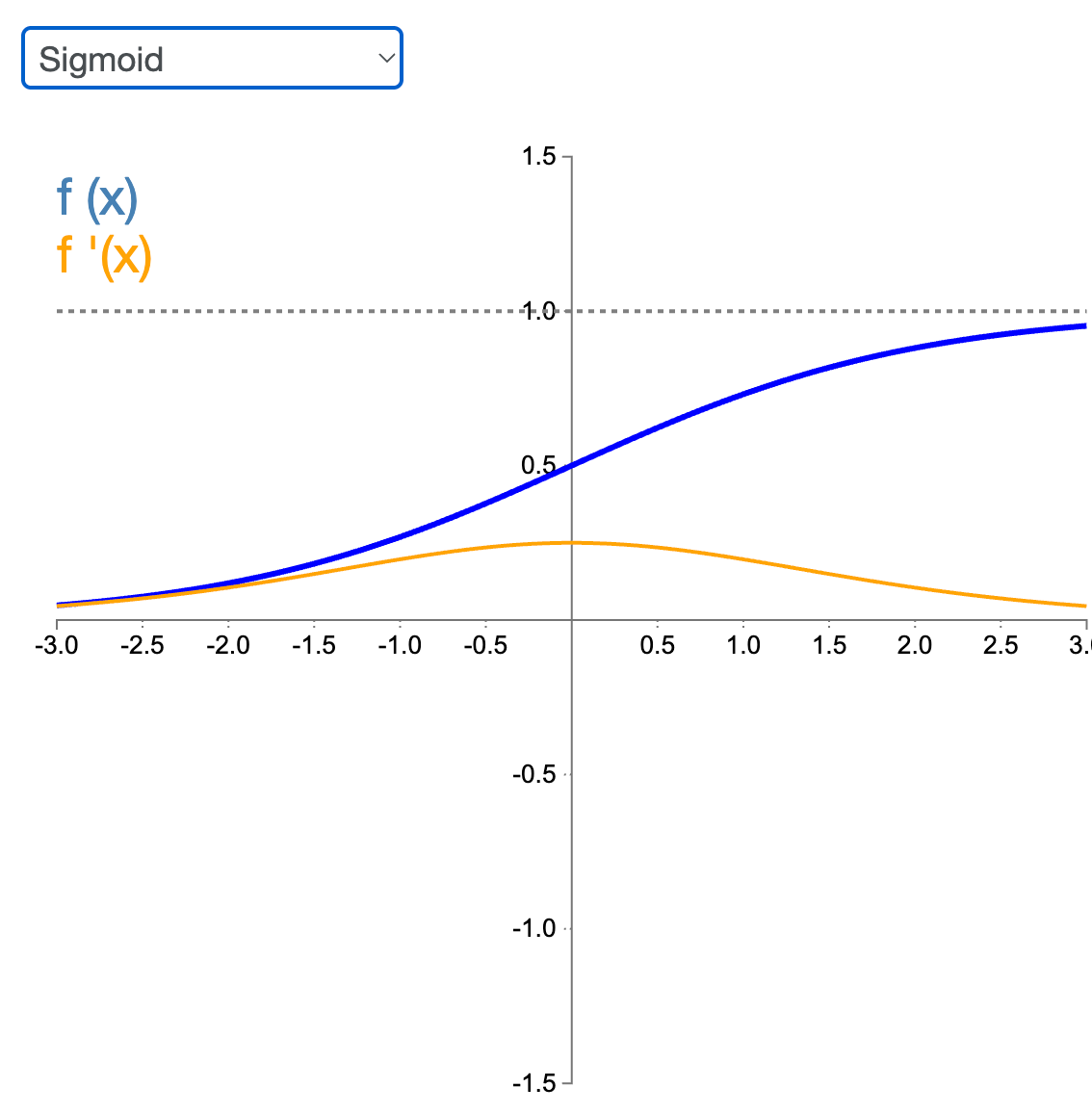
Sigmoid
The gradient is always non-zero (or between 0 and 1?), allowing gradient descent to make some progress at every step. But its gradient can become very small when the neuron saturates (for large positive or negative inputs). This leads to vanishing gradients, making training extremely slow.
It is commonly used in the output layer to enable classification tasks, because its output can be interpreted as probabilities.
How do we choose which one to use?
Each activation function has its plus and down sides. While ReLU is the most commonly used one, it has the drawback that it can literally kill a neuron. If all the outputs it receives are negative, the ReLU and its gradient will always give zero as well, preventing any further learning.
In some networks such as RNNs, LSTMs, and GANs, it is beneficial to replace the ReLU, with tanh. By having each layer output centered around 0 speeds up the training in these neural networks.
Activation functions can appear both in hidden layers and in the output layer. Relu and tanh are often found in hidden layers, while the sigmoid shines in the output layer. Its output can be interpreted as probabilities, and therefore perfect for classification.
I saw your post on LinkedIn, but didn't get a chance to connect there. I'm a mathematical physiciat publishing a new PDE theory of thermodynamics. If possible, I'd like to send you my idea for a physics-informed AI project.
The PDE generates 1/4 wavelength sine curves as Hamiltonian solutions. I don't know much about activation functions and back propogation, but it occurred to me that with just two experimental points on the monotonic solution curve (with an additional, defined left boundary at zero), an AI could solve the critical point (of each Hamiltonian contour) which is the right side, Neumann boundary (i.e. dy/dx = 0) with gradient descent (which I understand) but also activation and back propogation which I do not understand.
ebrownargenta@gmail.com
On LinkedIn search: Erik Brown Argenta
You described the concept in very simplistic way. Keep posting about basics of ML and DL in this manner. Looking forward to learning more from you.